Unlock a world of possibilities! Login now and discover the exclusive benefits awaiting you.
- Qlik Community
- :
- Forums
- :
- Archive
- :
- Archived Groups
- :
- QVD-Strategy with QDF: Extract and Transform Subfo...
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
QVD-Strategy with QDF: Extract and Transform Subfolders for 2.QVD?
Dear all,
for some weeks now I dived into QDF and am amazed: I think it is a great solution! Right now I am trying to find a suitable QVD-Strategy. After lots of redesign, the picture below shows my current structure:
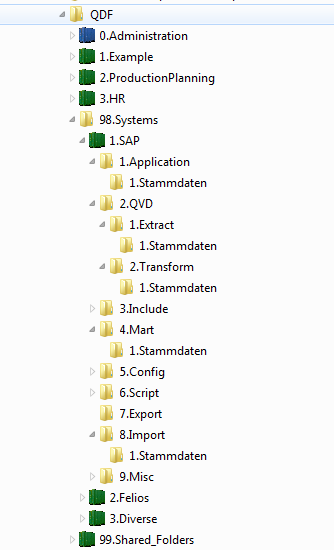
In order to enable a proper ETL-process, I created the subfolders 1.Extract and 2.Transform for 2.QVD of every container. I also modified the Example QVD-Generators so that they atomatically create one more level of subfolders like "1.Stammdaten" (Master Data in German): These subfolders are meant to group data within one sphere of application together.
The process goes like this;
1) Start 1st QVD-Generator in 1.Application\1.Stammdaten and extract e.g. data from 8.Import\1.Stammdaten
--> Create raw QVD-files in 2.QVD\1.Extract\1.Stammdaten
2) Start 2nd QVD-Generator in 1.Application\1.Stammdaten and transform these raw QVDs from 2.QVD\1.Extract\1.Stammdaten
--> Create transformed QVDs in 2.QVD\1.Transform\1.Stammdaten
3) Start the Mart under 4.Mart\1.Stammdaten
--> Load all transformed QVDs from 2.QVD\1.Transform\1.Stammdaten to build the data model
4) Start the final GUI under 1. Application\1.Stammdaten
--> Do a binary load on the Mart under 4.Mart\1.Stammdaten --> The App is ready for use!
My question now is: Are those subfolders 1.Extract and 2.Transform under 2.QVD really necessary? The QDF Development Guide mentions that you should use subfolders under 2.QVD, but maybe it is meant like this:
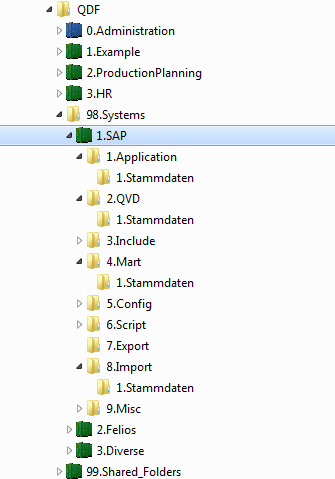
The advantage of this model is in my opinion that you do not need the 1.Extract and 2.Transform folder in cases when no transformation is necessary. Then all data files, QVWs and QVDs are just grouped in the project-specific subfolder like "1.Stammdaten" in this case. The QDF Development Guide also mentions that the Index Monitor is the key to locate and manage all QVDs on different levels. But if all QVDs reside under 2.QVD\subfolder, how do you differentiate between raw and X-Form QVDs and that they do not overwrite each other? Do you suggest a naming convention like TableName_EXT and TableName_TRA? I want to make sure that there is enough flexibility for self-service users to create apps without exhausting staging and a long process for non-critical Apps, but I also want to be able to follow this process for important apps where a lot of data cleansing and modeling is necessary.
Thank you in advance!
Accepted Solutions
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Georg, glad that you like the container concept. To answer your question. No you do not need extract/transform folders in the container, this is one way of working. We have added these folders in 1.5.1 from popular requests, the extract/transform/load folders inside QVD will generate corresponding global variables (example vG.ExtractPath), these subfolders are used primarily for smaller deployments where we want less "container complexity".
For a larger deployment I suggest separating raw and clean/transformed data within individually containers. Especially good when doing self-service, container access can be restricted only to the nice looking transformed QVD files. In this case the QVD Indexing is really neat, index only the transformed qvd files for easy self-service, just add one line of code to load up a complete data model  Hope that this helps?
Hope that this helps?
Best regards
Magnus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Georg, I agree with you the QDF is valuable! I too am sorta new to QDF and I'm not fully qualified to give you an experienced answer. However, I am doing work currently very similar to you.
I too have a System folder where I do Source system SQL to QVD loads and have sub folders under 1.Application for QVD generator and QVD Transformation. I do not use the System containers for Qlik mart or user level applications. I have varying degrees of transformation happening in the SQL. If you didn't do any transformation in SQL and your data really needs it to be usable I could see more of a need to use another transformation step. You could definitely use your naming convention that you suggested - or even use an Extraction folder and a Transformation Folder with their own containers. This is what I like about QDF it lets you design within it to make it work for you.
I do much transformation work in SQL, views on the source, or with resident loads within the Extraction step so I rely less on doing a transformation step in my System containers. I use a transformation QVD to QVD in my top level containers. This transformation primarily makes sure that the correct associates are made when the 4.Mart application blindly loads all the QVD files from the 2.QVD folder.
In my top level containers in my 1.Application level folder I have two subfolders: A 20.QVD Transformation folder and an 30.QVW Application folder which then gets shared on the QVS portal. The user level application does a binary load of the qvw in the 4.Mart folder

the QVD transformation prepare the source qvd's for the qlik mart
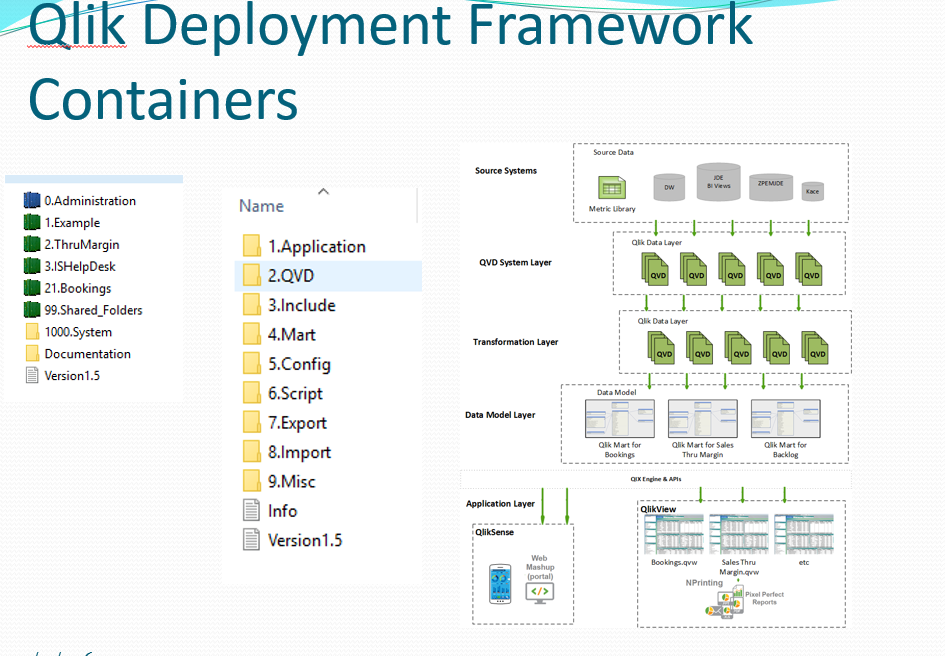
I hope this helps to get the conversation going!
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hi Georg, glad that you like the container concept. To answer your question. No you do not need extract/transform folders in the container, this is one way of working. We have added these folders in 1.5.1 from popular requests, the extract/transform/load folders inside QVD will generate corresponding global variables (example vG.ExtractPath), these subfolders are used primarily for smaller deployments where we want less "container complexity".
For a larger deployment I suggest separating raw and clean/transformed data within individually containers. Especially good when doing self-service, container access can be restricted only to the nice looking transformed QVD files. In this case the QVD Indexing is really neat, index only the transformed qvd files for easy self-service, just add one line of code to load up a complete data model Hope that this helps?
Best regards
Magnus
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Dear Andrew and Magnus,
thank you very much for these great explanations! I rethought a lot of things and now have a struture which I think can be migrated to the QVS. See the following picture:
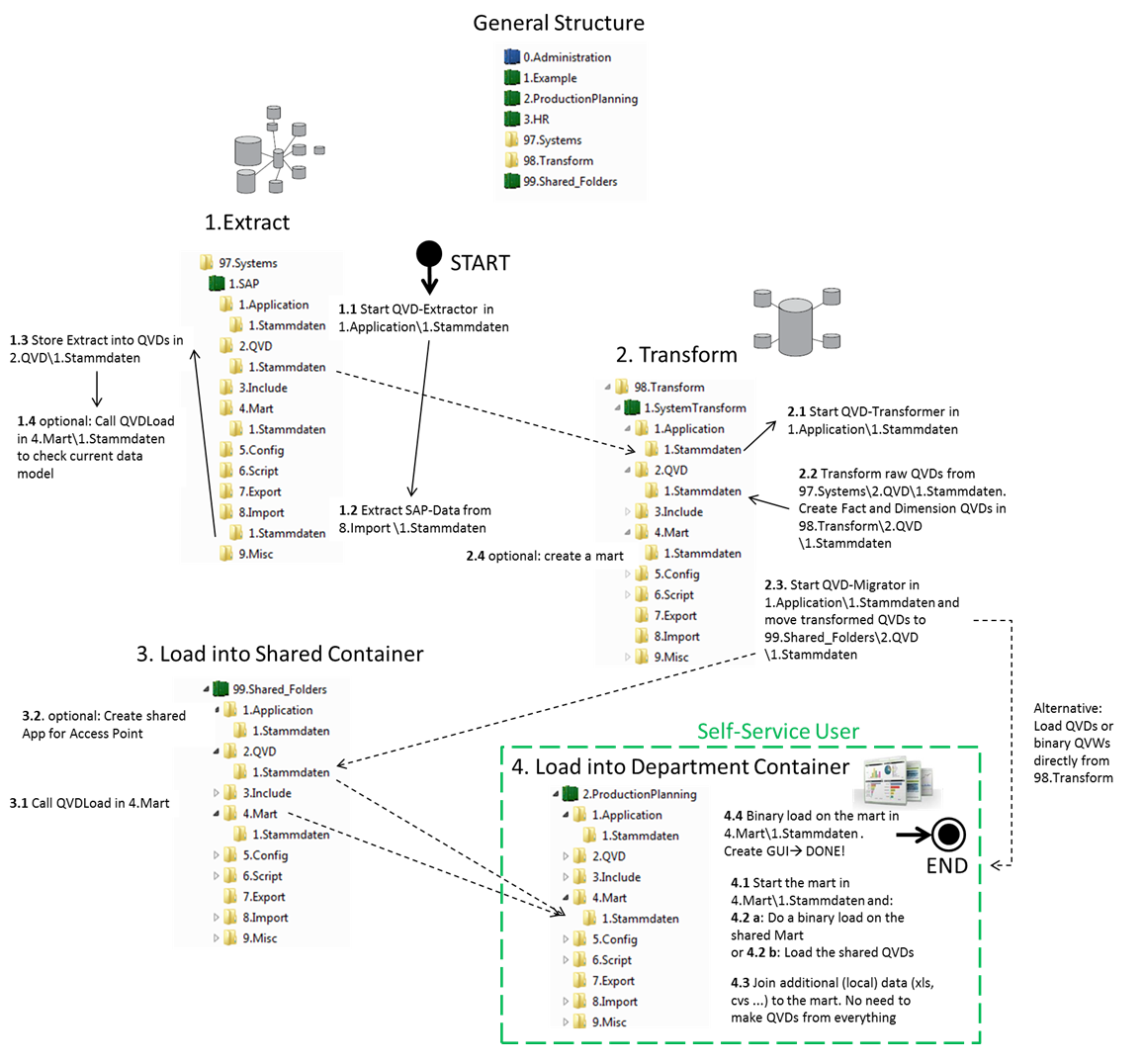
The data flows neatly in this model, I now omitted the subfolders for 1.Extract and 2.Transform. Just one subfolder for every sphere of related data. Now the transformation is done in a seperate container and only the transformed QVDs will be indexed as you suggested. In this example the "Stammdaten" (Master Data) are also shared company-wide so there is an additional self-service benefit for loads from every department or project container.
What do you think about this? Will it be suitable to follow a professional ETL-process while ensuring user flexibility at the same time? I am not sure about using the QVD-Migrator in 2.3 as well, but I did not want to have a direct connection pulling data from the transformation container. I will put the distribution on schedule at night.
P.S.: Please excuse my use of gigantic pictures, but I desperatley longed for such illustrations when starting with QDF and I hope that also helps others 
Regards,
Georg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
I like the idea you have Georg!
One further improvement to your model could be to separate data warehouse source systems from other source systems since the transformation need often differs a lot between these two types of source systems. In some cases they use a Self-Service model already in the data warehouse. In this case the raw-data layer in QlikView will be the same as the Self-Service layer.
Another thing is to get in control over the terms and definitions so that the same terms are used in all systems to make it possible to connect the data between them.
As a last point I would recommend you to separate source system QVD:s from application formatted QVD:s. This is not the same thing. Source system QVD:s should be possible to be used in several applications and you should be able to mix tables from different source systems as long as they connect with the same terms. In this scenario it is impossible to use data marts to support all combinations of tables and where-statements so I would skip data marts in the source system QVD-layers. In the application specific QVD-layers on the other hand data marts could be useful in some scenarios, but personally I don't use binary load that often in production solutions.
As I said I liked your idea and that's why I thought that you might be interested of also my thoughts and experiences to refine your good idea even further.
Best regards
Stefan
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Hello Stefan!
Thanks a ton for supporting the idea - I am the only QlikView developer here and self-taught by the books and other documentation. You encourage me to follow the path I came up with on this lonely way! Regarding your suggestion to split the source folders into Data Warehouse and Others, I think it is a good hint which I will certainly consider in the future. But right now we are not selecting from a Data Warehouse, we are just starting to introduce QlikView on a strong foundation. So it will be enough for the moment to have the 97.System folders - maybe already aggregated source could also directly be loaded into 98.Transform and combined there with other?
The terms and conditions definitely need to be controlled. That's one reason I decided for QDF because it at least gives you an overview about what is going on where. I think we will store files for common KPI's and related data in the Shared Container and distribute it from there or in some other way.
Concering source and application formatted QVD's, I agree: We also need to define their structure, but I must admit that right now we are not ready to design them for different applications - we don't know how they will look like in the end, yet! First priority is to structure processes and habits with QDF, teach the first users in QlikView and then start thinking like a professional application architect. I just put the marts in the QVD layers as an example in the picture above - but I am a fan of binary load! Definitely one function that offers some great possibilites in the Self Service later.
Best wishes,
Georg
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
Thanks for sharing Georg,
I came back to this conversation because I am now looking to implement a separate System Transformation Container. The main reason for this is I am using robocopy to sync my development machines and I want to exclude the large and easy to recreate qvd's that I generate during transformation steps. I was putting these in the system container but it is really slowing the robocopy down. Also, I am now doing more Transformation of system qvd's that are cross-system.
So thanks for sharing, I'm going to create a 1.SystemTransform container.
Andy